2025

Live-SWE-agent: Can Software Engineering Agents Self-Evolve on the Fly?
Chunqiu Steven Xia, Zhe Wang, Yan Yang, Yuxiang Wei, Lingming Zhang
🚀 Top-1 Open-Source Agent Performance on SWE-bench Verified
In this paper, we propose Live-SWE-agent, the first live software agent that can autonomously and continuously evolve itself on-the-fly during runtime when solving real-world software problems. More specifically, Live-SWE-agent starts with the most basic agent scaffold with only access to bash tools (e.g., mini-SWE-agent), and autonomously evolves its own scaffold implementation while solving real-world software problems. Our evaluation on the widely studied SWE-bench Verified benchmark shows that Live-SWE-agent can achieve an impressive solve rate of 75.4% without test-time scaling, outperforming all existing open-source software agents and approaching the performance of the best proprietary solution. Moreover, Live-SWE-agent outperforms state-of-the-art manually crafted software agents on the recent SWE-Bench Pro benchmark, achieving the best-known solve rate of 45.8%.
Live-SWE-agent: Can Software Engineering Agents Self-Evolve on the Fly?
Chunqiu Steven Xia, Zhe Wang, Yan Yang, Yuxiang Wei, Lingming Zhang
🚀 Top-1 Open-Source Agent Performance on SWE-bench Verified
In this paper, we propose Live-SWE-agent, the first live software agent that can autonomously and continuously evolve itself on-the-fly during runtime when solving real-world software problems. More specifically, Live-SWE-agent starts with the most basic agent scaffold with only access to bash tools (e.g., mini-SWE-agent), and autonomously evolves its own scaffold implementation while solving real-world software problems. Our evaluation on the widely studied SWE-bench Verified benchmark shows that Live-SWE-agent can achieve an impressive solve rate of 75.4% without test-time scaling, outperforming all existing open-source software agents and approaching the performance of the best proprietary solution. Moreover, Live-SWE-agent outperforms state-of-the-art manually crafted software agents on the recent SWE-Bench Pro benchmark, achieving the best-known solve rate of 45.8%.

PurpCode: Reasoning for Safer Code Generation
Jiawei Liu*, Nirav Diwan*, Zhe Wang*, Haoyu Zhai, Xiaona Zhou, Kiet A. Nguyen, Tianjiao Yu, Muntasir Wahed, Yinlin Deng, Hadjer Benkraouda, Yuxiang Wei, Lingming Zhang, Ismini Lourentzou, Gang Wang (* equal contribution)
🥇 1st Place in Amazon Nova AI Challenge 2025 ($250,000)
NeurIPS 2025
We introduce PurpCode, the first post-training recipe for training safe code reasoning models towards generating secure code and defending against malicious cyberactivities. PurpCode trains a reasoning model in two stages: (i) Rule Learning, which explicitly teaches the model to reference cybersafety rules to generate vulnerability-free code and to avoid facilitating malicious cyberactivities; and (ii) Reinforcement Learning, which optimizes model safety and preserves model utility through diverse, multi-objective reward mechanisms.
PurpCode: Reasoning for Safer Code Generation
Jiawei Liu*, Nirav Diwan*, Zhe Wang*, Haoyu Zhai, Xiaona Zhou, Kiet A. Nguyen, Tianjiao Yu, Muntasir Wahed, Yinlin Deng, Hadjer Benkraouda, Yuxiang Wei, Lingming Zhang, Ismini Lourentzou, Gang Wang (* equal contribution)
🥇 1st Place in Amazon Nova AI Challenge 2025 ($250,000)
NeurIPS 2025
We introduce PurpCode, the first post-training recipe for training safe code reasoning models towards generating secure code and defending against malicious cyberactivities. PurpCode trains a reasoning model in two stages: (i) Rule Learning, which explicitly teaches the model to reference cybersafety rules to generate vulnerability-free code and to avoid facilitating malicious cyberactivities; and (ii) Reinforcement Learning, which optimizes model safety and preserves model utility through diverse, multi-objective reward mechanisms.

MultiAgentBench: Evaluating the Collaboration and Competition of LLM agents
Kunlun Zhu*, Hongyi Du*, Zhaochen Hong*, Xiaocheng Yang*, Shuyi Guo*, Zhe Wang*, Zhenhailong Wang, Cheng Qian, Xiangru Tang, Heng Ji, Jiaxuan You (* equal contribution)
ACL 2025 Main
In this paper, we introduce MultiAgentBench, a comprehensive benchmark designed to evaluate LLM-based multi-agent systems across diverse, interactive scenarios. Our framework measures not only task completion but also the quality of collaboration and competition using novel, milestone-based key performance indicators.
MultiAgentBench: Evaluating the Collaboration and Competition of LLM agents
Kunlun Zhu*, Hongyi Du*, Zhaochen Hong*, Xiaocheng Yang*, Shuyi Guo*, Zhe Wang*, Zhenhailong Wang, Cheng Qian, Xiangru Tang, Heng Ji, Jiaxuan You (* equal contribution)
ACL 2025 Main
In this paper, we introduce MultiAgentBench, a comprehensive benchmark designed to evaluate LLM-based multi-agent systems across diverse, interactive scenarios. Our framework measures not only task completion but also the quality of collaboration and competition using novel, milestone-based key performance indicators.
2024
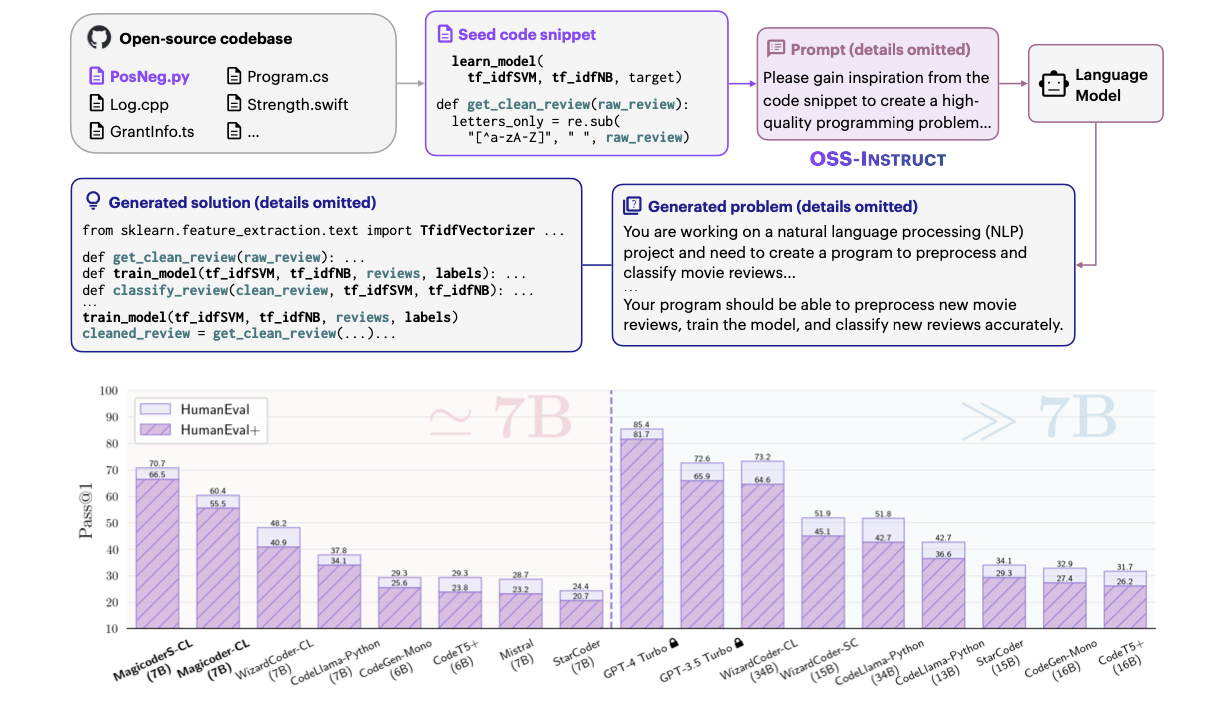
Magicoder: Empowering Code Generation with OSS-Instruct
Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, Lingming Zhang
ICML 2024
In this paper, we introduce Magicoder, a series of fully open-source (code, weights, and data) Large Language Models (LLMs) for code that significantly closes the gap with top code models while having no more than 7B parameters.
Magicoder: Empowering Code Generation with OSS-Instruct
Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, Lingming Zhang
ICML 2024
In this paper, we introduce Magicoder, a series of fully open-source (code, weights, and data) Large Language Models (LLMs) for code that significantly closes the gap with top code models while having no more than 7B parameters.